
Together, We Are Innovators
Success takes on-demand collaboration with diverse leaders and thoughtful minds within our network of clients, Microsoft, and 3Cloud. Everyday we innovate, take risk and experiment with new ideas that solve complex challenges, fuel resilience and reinvent your business.
Explore our client stories >





Azure. It’s what we do.
With a 100% focus on Azure, our experts deliver to you the ultimate Azure experience — for your internal teams and external customers. Make the cloud work for you with our Azure services.
Access Project Funding
Seize opportunities to use Microsoft project funding for your cloud-based initiatives.
Accelerate Adoption
Transition to Azure faster and more effectively, leveraging our expertise at every phase.
Modernize Systems
Expand the functionality and capability of your on-prem and cloud systems with Azure.
Automate & Optimize
Start streamlining operations with 3Cloud’s Azure solution accelerators.
Evolve Your Business
Take your business to the next level with scalable Azure solutions.
Are you struggling to start with AI? 3Cloud can help you identify your starting point and achieve proof of value.
Discover the cloud solutions you need to achieve your business transformation goals.
Enhance your existing apps to take full advantage of native cloud security, scalability and efficiencies. Build new apps and services with a cloud-first perspective that helps you maintain a competitive advantage.
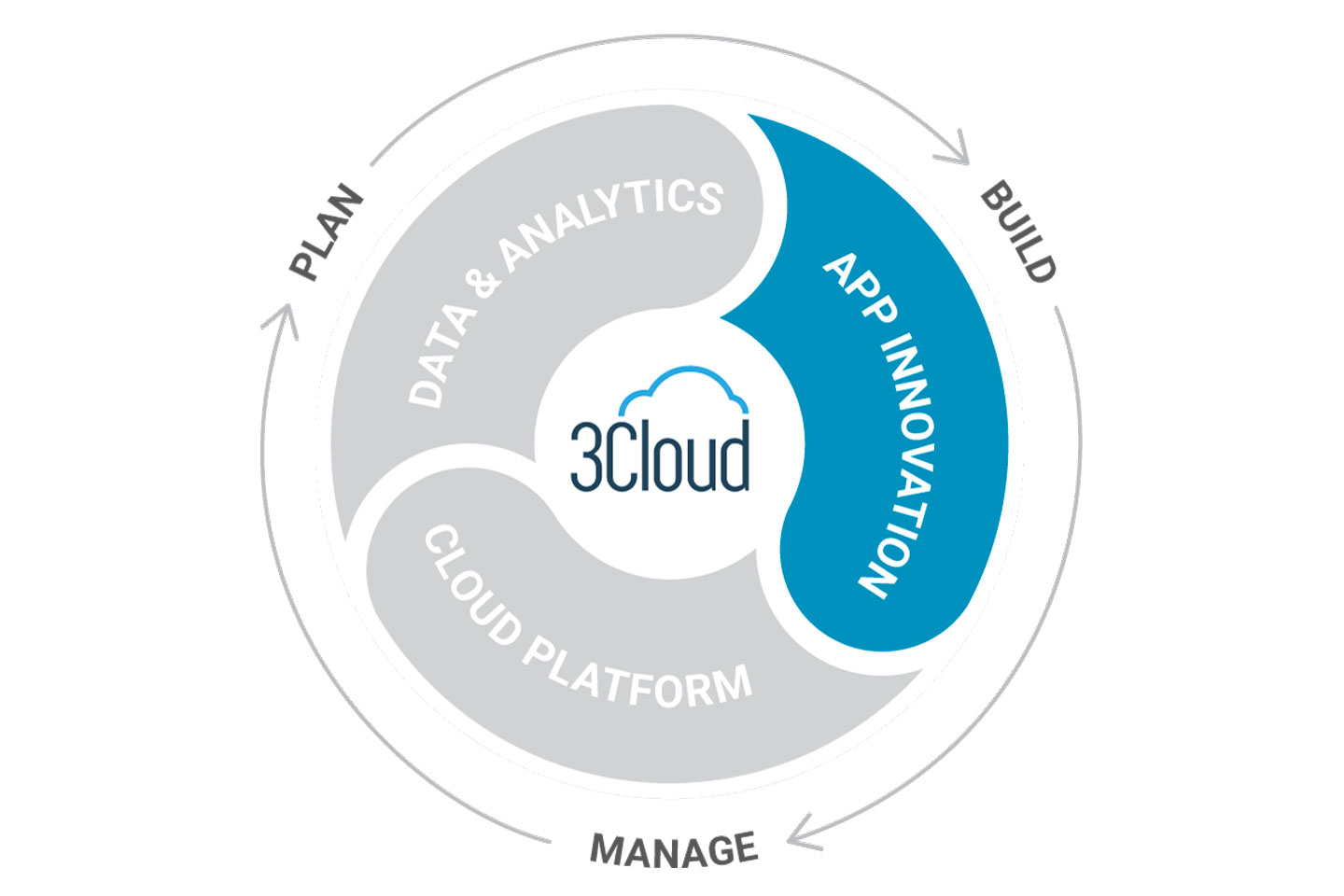
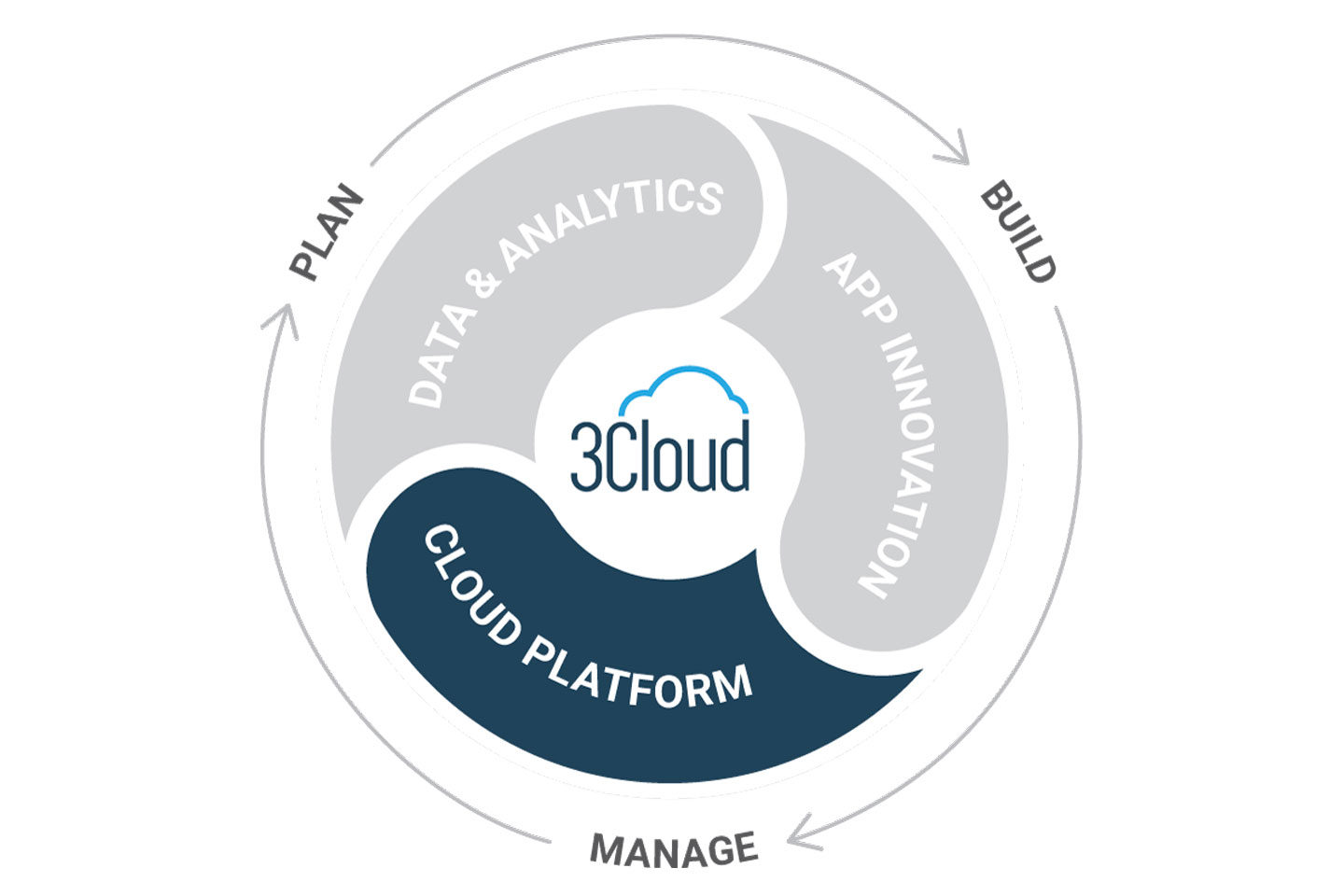
Create a secure and manageable foundation for your applications and data with Azure cloud. Leverage our best practices to implement repeatable, scalable architectures to meet your needs, today and tomorrow.
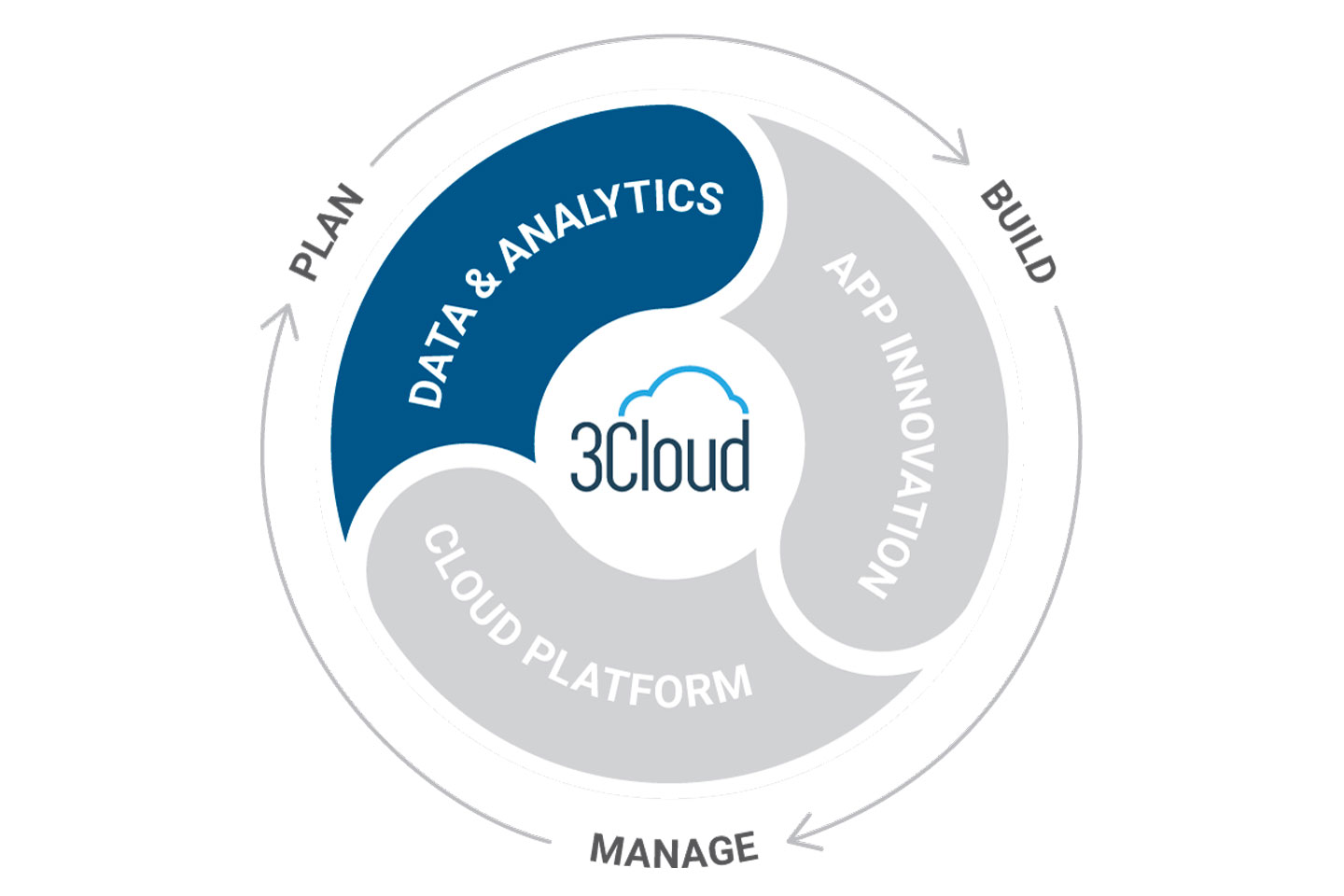
Make better business decisions with insights from your data. Increase visibility and drive enhancements related to efficiency, innovation and customer experience using a modern data platform powered by Azure.
Where are you on your cloud journey?
No matter where you are in your cloud migration journey, our experts help advise, architect, build, and optimize your Azure cloud environment to transform your business.
MIGRATE
Whether you’re migrating your data center, data estate or application portfolio – we’ll help you strategically move your workloads and applications to Azure.
MODERNIZE
Optimize your applications, data, analytics and infrastructure to fully take advantage of the robust Azure cloud platform.
BUILD
Easily develop new applications, new ways to leverage your data or a new DevOps foundation as a basis for your digital transformation.
MANAGE
Focus on your business, not your cloud platform, while our managed services team ensures a stable, secure and optimized Azure environment.

Use our Azure Economic Assessment to determine where you are in your cloud transformation journey and how Azure services can move your organization forward.
Work with smart people to do cool things with Azure.
The brightest minds in Azure choose 3Cloud. Work alongside industry leaders to build new solutions, solve complex challenges, and build an organization that makes you proud.
Put your stamp on a growing technology company and build the career you want alongside good people who believe the future is ours to create.

Explore resources developed by our industry leaders that dive deep into Azure and parse topics related to data, storage, analytics, and more.

Operationalize the cloud and enjoy the ultimate Azure experience with the experts at 3Cloud.


