Data warehousing in the cloud has become a hot topic for most organizations as data volume grows exponentially, and yet the capacity to manually manage it all but diminishes. The ecosystem is replete with options, each with a host of features and integrations. In this article, we will discuss two of the most common (and commonly discussed!) data warehousing services, Azure Synapse and Snowflake Data Warehouse (DW). For this article, we will focus on areas of similarity as well as differentiators, and provide some context for evaluation.

Snowflake DW: A Brief Overview
Snowflake, as a company, was founded in July of 2012 and built their organization around the success of their data warehousing solution. This service, along with their ongoing support for it, is their sole focus. As a result, the polish given to this product creates a high shine, and the team is proud to promote their ‘free-think’ approach to the domain.
This data warehouse is a multi-cloud software as a service (SaaS) solution, and is built on the back of the major cloud provider’s storage options. This means a Snowflake DW is backed by an Azure Storage Account, an AWS S3 account, or a GCP Cloud Storage instance. It is worth noting that Snowflake’s model means that the DW is technically on their (Snowflake’s) cloud instance in whichever public cloud it is deployed, and not the customer’s. This is at least somewhat due to their approach to compute: Snowflake maintains a collection of pre-provisioned (and pre-warmed) virtual machine (VM) instances, for the sake of compute. Snowflake also features their own ANSI-compliant (to an extent) SQL dialect, called SnowSQL.
The primary difference between Snowflake and most other DW offerings is the fully decoupled compute and storage.
This means, from the perspective of your data warehouse, compute and storage are merely services to be called in to. Storage is the external account set during provisioning, and compute is procured at query-time from the existing VM pool. This compute capacity is allocated in so-called “t-shirt sizes” (small, medium, large, etc.) with each step up the size chart representing a doubling of the number of VM’s concurrently processing the data. When a query is submitted, it is compiled and distributed to the compute nodes, data is procured, and processing is completed, collated, and returned.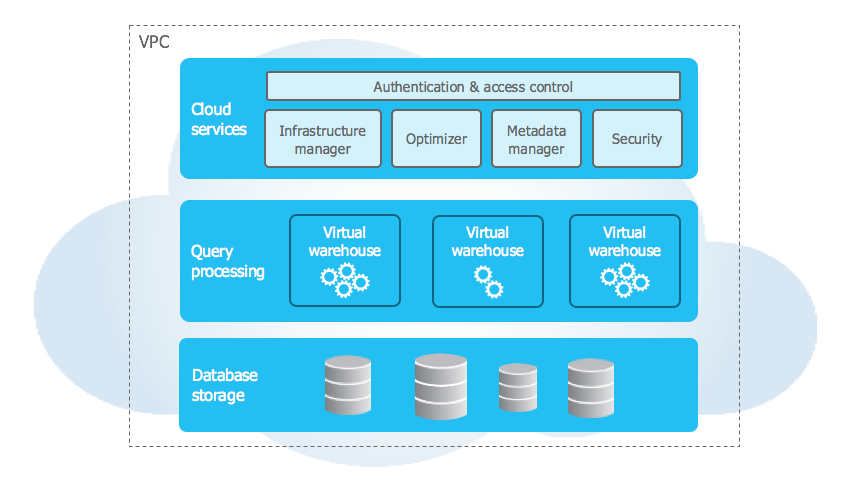
Synapse: Revolutionary Integration
Synapse, by contrast, is a very new (circa Dec. 2020) data platform offering from Microsoft, built to fulfill a somewhat different role in the big data ecosystem. While it has long-standing roots in Microsoft’s award winning Massively Parallel Processing (MPP) database work that spans both on-premises appliances and the cloud (PDW -> APS -> Azure SQL DW), it has rebranded since adding an otherwise unmatched collection of services into a single platform.
Synapse offers an end-to-end integrated data experience,
which allows querying of data without a dedicated pool.
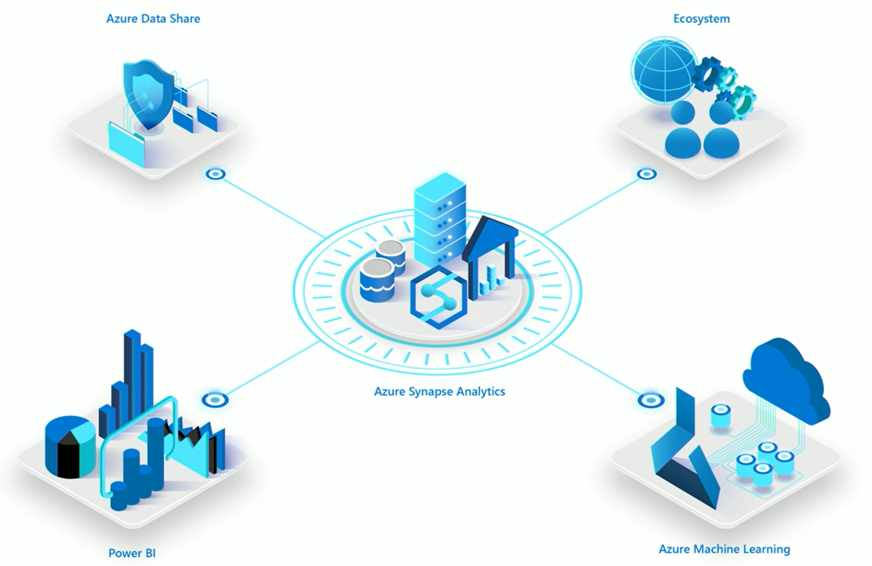
Synapse offers integration to Azure Data Factory (ADF) pipelines, SQL DW Dedicated Pools, Synapse Serverless, and even Spark Pools, as well as compatibility with many other compute and storage services by virtue of the Azure Data Factory integration.
Synapse is regarded as a PaaS (platform-as-a-service) solution and effectively represents an integration of numerous existing Microsoft data solutions. This integration is natively presented in the Synapse Studio experience, which is the front-end of Synapse. It allows for development, monitoring, and more.
Synapse Studio includes direct development experiences for the following services/platforms:
- Azure Data Factory, relabeled as Synapse Pipelines (slightly different than ADF proper, but is an extremely familiar experience)
- Spark Notebooks, which run on pre-provisioned Spark pools
- Dedicated SQL Pools, previously known as SQL Data Warehouse, provide a modern distributed data warehouse platform with standard ANSI-compliant SQL programming interface
- Serverless SQL Pools provide an additional ANSI-compliant SQL interface to data stored directly in the data lake, including support for raw data in delimited or JSON formats, or curated data in Parquet or Delta Lake format
- Azure Data Lake Storage, enabling exploration within the studio
- Mapping Data Flows, featuring similar integration as ADF
- Azure Purview, which can connect directly to Synapse Pipelines
- and Power BI, to allow data visualization and analytics on all of your data!
What’s the same?
Given that both offerings aim to fulfill the Data Warehouse role in a stack, there are bound to be similarities. Here are the most important ones:
- Separate compute and storage pricing: both allow varying levels of compute and storage, managed separately from the other pieces
- Scale/Pause/Resume compute
- ANSI-SQL compliant (to an extent) SQL API
- Support for both structured and semi-structured data sources
- Data virtualization: both allow you to drop a file and query it by specifying a format (CSV/Parquet/JSON etc.)
- Delta lake support (Snowflake requires an additional manifest file)
It is worth noting that Data Factory natively supports Snowflake as a Source or Sink, meaning it ‘inherits’ many features ADF provides. This includes Databricks integration, Spark jobs, Batch jobs, Azure Functions calls, etc. There also exists a complete connector feature for Snowflake, meaning it can be integrated to many existing .NET stacks. It’s worth noting, however, that there is no feature complete .NET EntityFramework/Core provider, though this may be less important for an OLAP offering.
So… What’s Different?
Aside from the obvious (software model, cloud support, etc.), there are some features that are conceptually similar, but materially different.
- Scale Compute: Synapse uses an obfuscated Data Warehouse Unit (DWU) to scale compute at a relatively fine grain, while Snowflake uses “t-shirt” sizes which correspond to the quantity of Virtual Machines utilized for compute. Synapse couples a compute instance (dedicated pool) to a single database (except for serverless), while Snowflake fully decouples compute, meaning a compute instance can run with any database or data set.
- Cost: Synapse lists prices by the hour at various DWU levels (for dedicated pools, serverless charges based on ingress/egress), while Snowflake lists pricing for compute by the ‘credit’, and aligns the ‘credit’ consumption to the T-Shirt sizing of your compute as well as a product tier (Standard, Enterprise, Mission Critical) – however, both services actually charge by the second.
- Queries: Snowflake features Cross-database queries, while Synapse supports this in certain cases, such as in Serverless instances. Synapse Pipelines allow for trigger-based file loads, while Snowflake allows the creation of SnowPipes, which provide roughly the same functionality.
- Integration: Snowflake integrates fairly well in an Azure stack, and Synapse can play nicely with other clouds, based on its ADF connectors.
- Data Sharing: Data Sharing is built directly into the Snowflake experience, and Synapse allows this through the complementary ‘Azure Data Sharing’ service.
- Indexing: While both services have something akin to indexing, there are a few important differences to note. Synapse features a typical indexing experience, but also automatically indexes data. Additionally, to empower its Massively Parallel Processing (MPP) backend, Synapse benefits greatly from partitioning of data on ‘disk’. Snowflake features no support for manual indexing, opting instead for a ‘perform by default’ paradigm. Snowflake also recommends a clustering key is maintained for very large tables in the multiple-terabyte-plus range.
- Synapse offers enterprise business critical security and protection in a single pricing tier, and all compute is dedicated per customer and billed per usage unit (DWU). Snowflake can support high security scenarios up to and including dedicated compute support at a higher price point.
Snowflake Pros
Snowflake has some notable strengths:
- Snowflake features a free trial, meaning a developer can start an account, and try it out, without the risk of wasted capital. While there are routes to get trial credits for Azure, there is no Synapse-specific trial, meaning you must either pay, or use your credits to test it out.
- Snowflake resume times are generally faster, as they try to maintain a shared pool of warm instances.
- Snowflake has support for XML data types and parsing. Synapse supports constructing/deconstructing XML documents, but they are stored as unparsed ‘VARCHAR’ fields. Snowflake also features a (subjectively) better JSON experience.
- Snowflake supports ‘Auto-pause’ of compute resources, which can be quite helpful with larger warehouses and keeping costs down.
-
Snowflake private data exchange capabilities provide a streamlined front-end.
Synapse Pros
This section could be even more replete, and the reason for this is simple. It’s fair to say Snowflake tries to do one thing very well: data warehousing, but Synapse aims to do something bigger by integrating the entire data platform. Because of this disparity in purpose, there are a large number of things Synapse does that Snowflake simply does not.
In a nutshell:
- Source control integration: Synapse natively integrates with Github and ADO as source control systems.
- CI/CD for Synapse is supported via Azure DevOps, while Snowflake requires more manual steps.
- Built-in integration engine: Synapse Pipelines offers an SSIS-like experience, with a GUI-based development experience of ETL processes.
- Spark pool and Notebook integration: Synapse offers ad-hoc spark notebooks to be run, as well as Pipeline-based notebook calls.
- Allows for a Hybrid Transactional-Analytical Processing (HTAP) paradigm using Synapse Link.
- Built in Power BI integration allows fast and easy data exploration and visualization.
- Native integration with AAD (Azure Active Directory), Azure Key Vault, and by extension SSO (Single Sign On) is as simple and straight forward as it gets.
Additionally, Synapse can be set up and running in a few minutes, at most. Part of the integrated experience is the integration of all the disparate services in the spin-up experience. Synapse creates everything it needs, connects to data lakes in seconds, and makes it all available instantly. Snowflake can take a bit longer, especially if one intends to bring their own storage, or may not yet have all the necessary security and access control features in place.
The Final Act
When considering which data warehouse to use, as stated earlier, it’s extremely important to consider your use case. Snowflake DW performs well, integrates reasonably well, and features a fairly well-understood and practiced set of paradigms. Synapse, by contrast, integrates just about as well as is possible, and offers a more diverse experience for data processing and database type. As convenient as it would be to have a simple flow chart directing you to the appropriate choice, as with most things, it’s never quite that simple.
For a .NET stack or Azure-only environment, Synapse is an easy win, and a no-brainer. All services integrate natively, performance is certainly sufficient, and the experience matches that of existing .NET services. For a more diverse stack, or on a different cloud, Snowflake is a strong competitor, as their flexible compute and strong performance should be considered. While it is certainly not completely black and white, the broader vision of Synapse and native integrations with the incredible breadth of Azure services and Power BI has solidified 3Cloud’s focus on leveraging Synapse as a foundational element when delivering Modern Analytics solutions!
Contact 3Cloud
3Cloud has strong experience deploying Azure Synapse Analytics in organizations of all sizes. If you’re interested in learning more about how proper data warehousing can fit into your modern analytics journey, contact us today!
3cloud offers a variety of resources to help you learn how to leverage Modern Data Analytics for your organization, as well as events to jumpstart your vision. Get started with 3Cloud today.