While 2020 has not allotted many celebrations, it has been a great year for technology innovation in the modern data platform space. Microsoft and Databricks have been hitting it out of the park with new innovative features that will definitely increase solution value for customers and make Data Engineers and Data Scientists giddy.
In this two-part blog post, we’ll highlight the top 5 modern data platform technology features that have come out in 2020 that we’re excited about and that you need to get up to speed on. For ease of explanation, we’ve grouped our feature topics by technology partner. In the post below, we’ll discuss our top new features to the Databricks platform. In post two, we’ll discuss our top new features by Microsoft.

1) Spark 3.0
2020 marks Spark’s 10-year anniversary as an open source project. With this milestone also came the release of Spark 3.0 in June. The feature highlights include:
- Improvements to the Spark SQL Engine
- Improvements to Pandas APIs
- New UI for Structured Streaming
Spark SQL Improvements
Spark SQL is the workhorse of most Spark applications. With this in mind, several new features were added in Spark 3.0 to increase overall runtime performance.
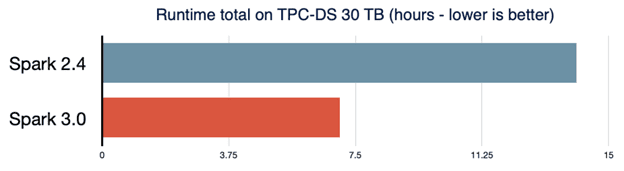
The new Adaptive Query Execution framework improves performance by generating more efficient execution plans at runtime. Executions are improved by dynamically coalescing shuffle partitions, dynamically switching join strategies, and dynamically optimizing skewed joins.
Dynamic Partition Pruning is another new feature which results in queries executing between 2x and 18x faster. This pruning is applied when the optimizer is unable to distinguish which partitions can be skipped, a common issue among star schemas. By identifying the partitions in filtering dimension tables, those partitions can be pruned from joins on the fact table.
Finally, Spark 3.0 also comes with improvements to ANSI SQL compliance, a crucial necessity for migrating workloads from SQL engines to Spark SQL. ANSI SQL establishes a standard for SQL in Spark that had been previously lacking. To enable with new code as well as preserve any older code, a simple configuration can be added:
![]()
Improvements to Pandas APIs
Python is now the most utilized language on Spark, as a result, a large amount of focus was concentrated on Python related improvements for this release. Pandas UDFs received several reboots including a new interface that uses Python hints to address the UDF type. Previously, UDF’s required non-intuitive type inputs such as SCALAR_ITER and GROUPED_MAP. Now UDF’s can handle types python users are more accustomed to such as pd.Series or pd.Dataframe. Overall, this results in an interface that is more Pythonic and easier to understand.
Two new UDF types were also added in this release: iterator of series to iterator of series and iterator of multiple series to iterator of series. Iterator of Series to Iterator of Series is expressed as:
Iterator[pd.Series] -> Iterator[pd.Series]
and results in an iterator of pandas Series as an output. This type is useful when the UDF requires an expensive initialization. Iterator of Multiple Series to Iterator of Series is expressed as:
Iterator[Tuple[pandas.Series, …]] -> Iterator[pandas.Series]
This type is similar in usage to Iterator of Series to Iterator of Series except that it’s input requires multiple columns.
Another Python feature in Spark 3.0 is the new Pandas Function APIs. This allows users to apply Python functions that both require and output Pandas data frames against PySpark data frames. These functions include grouped map, map, and co-grouped map. Both the grouped map and co-grouped map can be accessed by simply calling .applyInPandas() after the grouping. To apply the map function the command is df.mapInPandas()
Spark 3.0 also sees an improvement in PySpark error handling. Exceptions are now simplified and the often extensive and unnecessary JVM stack trace output is now hidden.
New UI for Structured Streaming
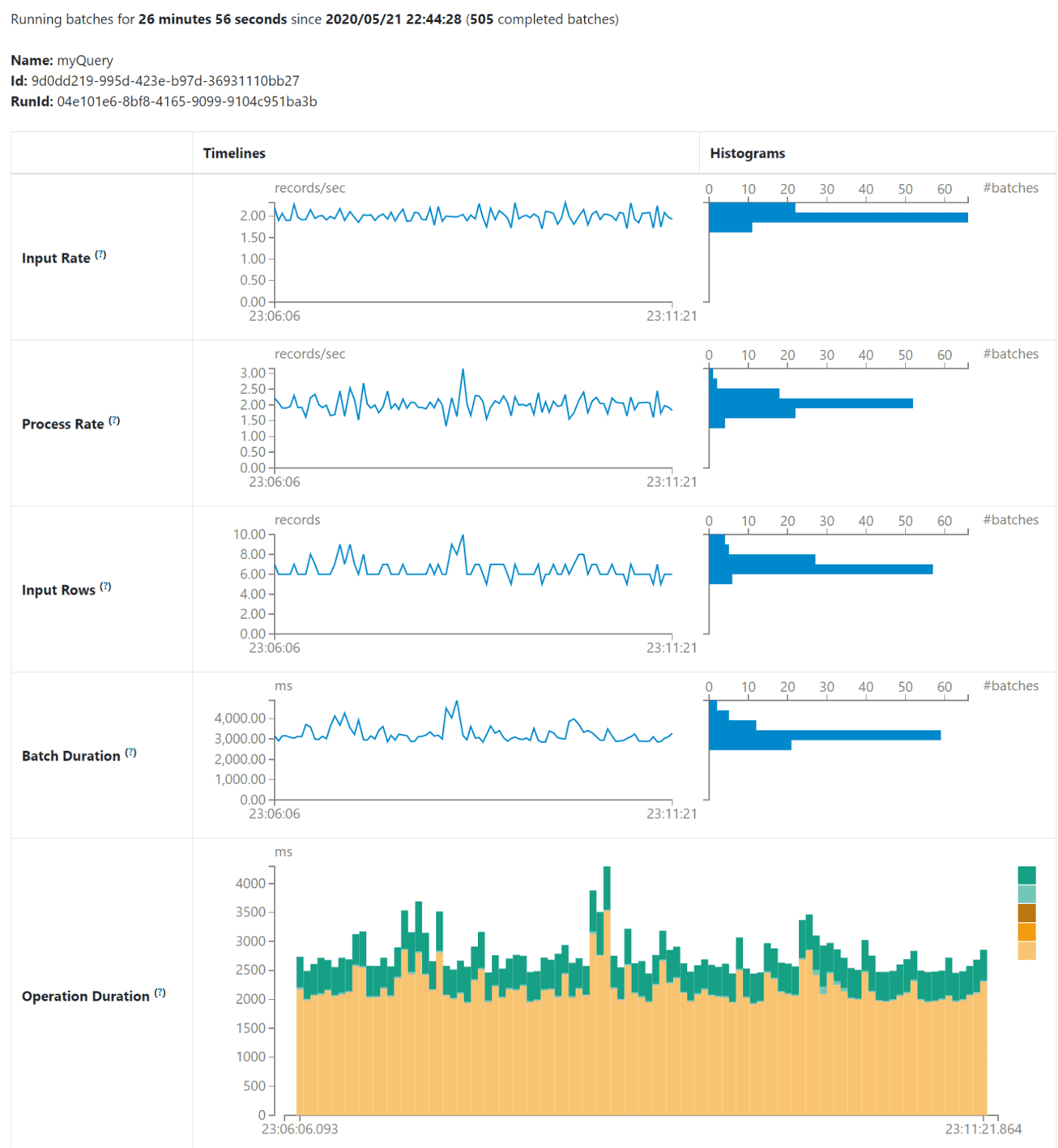
Spark 3.0 now includes a dedicated UI for monitoring streaming jobs. The UI offers both aggregated metrics on completed streaming query jobs as well as detailed statistics on streaming jobs during execution. The metrics currently available include:
- Input Rate – Aggregation of data arriving rate
- Process Rate – Aggregation of Spark processing rate
- Input Rows – Aggregation of the number of records processed in a trigger
- Batch Duration – Process duration for a batch
- Operation Duration – Time in milliseconds to perform various operations
Exceptions of failed queries can also be monitored. This UI is accessible from a Structured Streaming tab within the Web UI. Below is an example of what a user can expect to see during a streaming job:
Overall, the goal of Spark 3.0 is to not only improve runtimes and execution efficiency but provide a more user-friendly experience.
2) Delta Engine
Databricks also provided exciting 2020 advancements in the Modern Data Platform realm through the release of Delta Engine. Delta Engine is a high-performance query engine designed for speed and flexibility. Not only is it completely compatible with Apache Spark but it also leverages Spark 3.0’s new optimization features, as discussed above, to accelerate queries on data lakes, especially those enabled by Delta Lake.
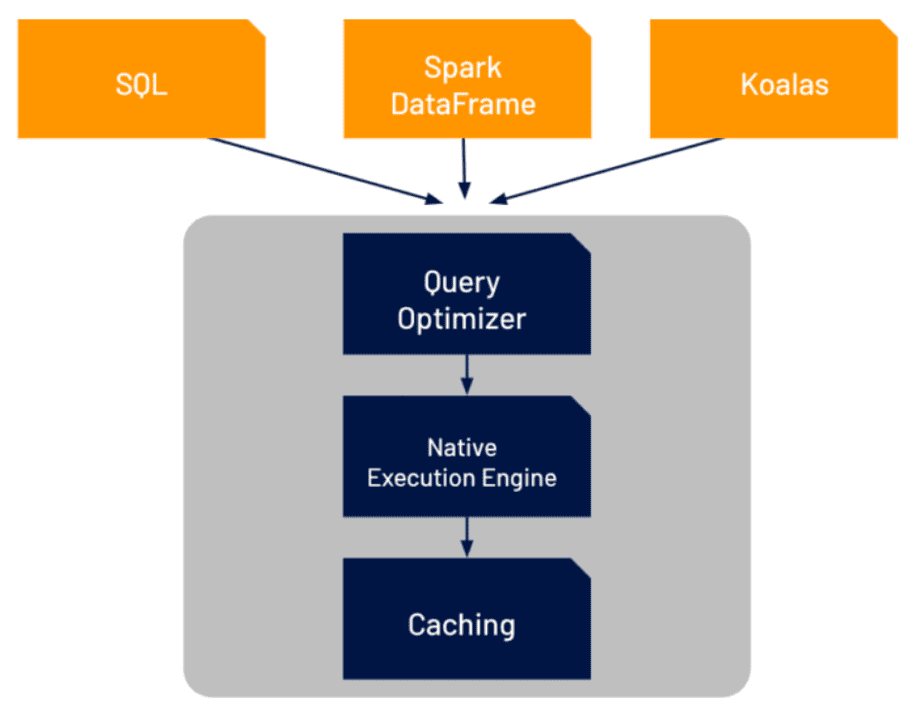
Delta Engine operates through three main components: query optimizer, caching layer, and a native vectorized execution engine. The query optimizer combines the Spark 3.0 functionally with advanced statistics to deliver an 18x performance increase in star schemas. The caching layer sits between the execution layer and the cloud storage. It automatically assigns the input data to be cached for the user. However, perhaps the most novel aspect of Delta Engine is the native execution engine called Photon. This engine is written specifically for Databricks to maximize performances for all workload types while maintaining Spark API compatibility.
Delta Engine is also user friendly in the fact that most of the optimizations take place automatically; in other words, the benefits are achieved by simply using Databricks in conjunction with a data lake. Overall, Delta Engine’s strength lies in its ability to combine a user friendly, Spark compatible engine with fast performance on real world data and applications.
The best part about these new Databricks features is that they are available today in any Databricks runtime of 7.0+. To learn more about how Spark 3.0 and Delta Engine can improve your modern data platform, Data Engineering, and Data Science solutions, contact 3Cloud today.
Stay tuned for our next blog post on top 2020 Modern Data Platform features released by Microsoft and Databricks.