
Microsoft and 3Cloud have blogged recently about the release of Azure SQL Data Warehouse (Azure SQL DW) Gen2. This post is a deeper dive into the practical application of some of the specific capabilities revealed in those announcements.

To put the platform through its paces, we will need a lot of data. So, we’ll start by using Azure Data Factory V2 to pull the last 100 years of weather data from the National Oceanic and Atmospheric Administration (NOAA) directly from the Http source into Blob storage.
Next, we load this data into Azure SQL DW Gen 2 using PolyBase. At DW1000c, the smallest scale for Gen 2, using mediumrc resource class, with source data in compressed (gzip) csv format exactly as it came from NOAA, this took 33 minutes and 24 seconds. This has now given us about 2.5 billion rows to work with. (Incidentally, our table is partitioned by year.)
For our first scenario, we want to visualize this data in Power BI. But, first we’ll use the massively parallel processing power of Azure SQL DW Gen 2 to reduce the size of our dataset by filtering and aggregating our daily observations, per station, into total annual rainfall by U.S. county. In my environment, this query completes in about 3 minutes, yielding about 282K rows.
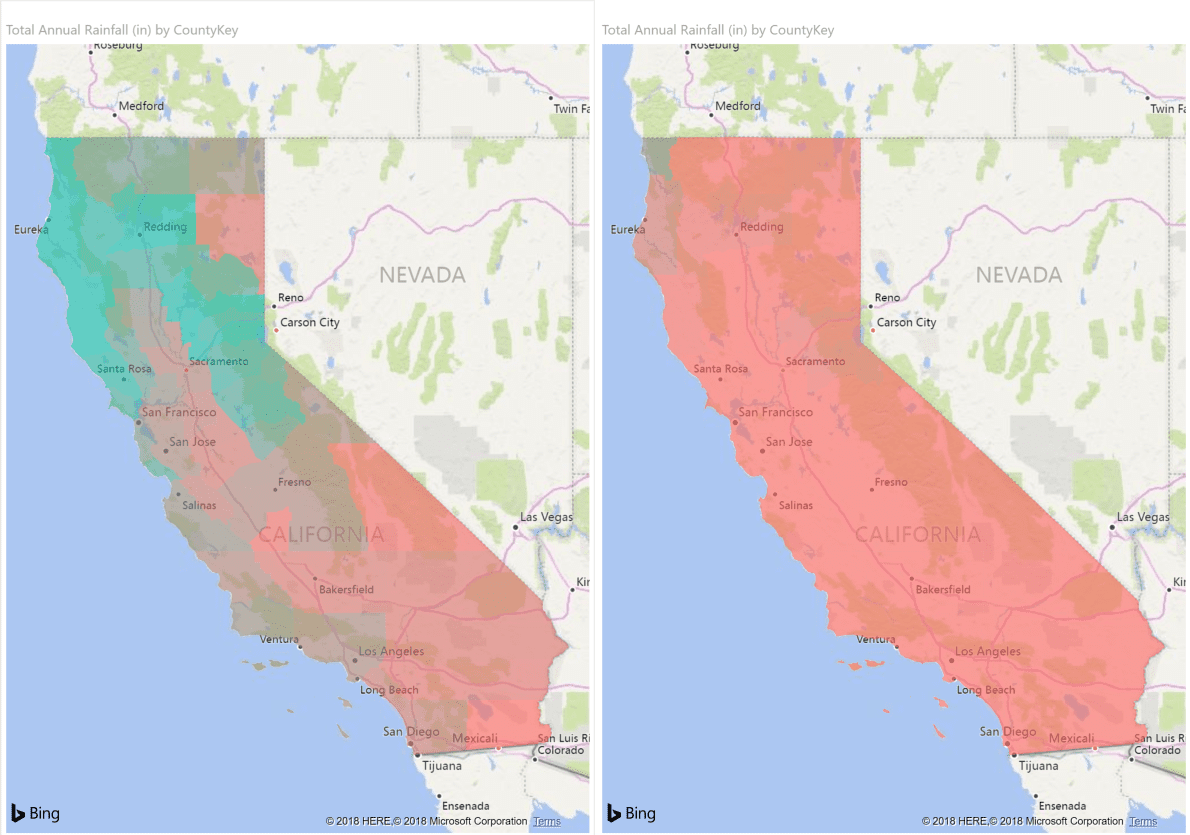
We can now use this data to analyze, for example, the California drought. Looking over the last 30 years, we can see that the wettest year during this period was 1998 (left), compared to the driest in 2013 (right). We can also see the areas of greatest impact.
For our final scenario, we will again visualize the data in Power BI, but first we’ll employ Azure Analysis Services (AAS) to import the full, unaggregated dataset for in-memory analytics and, in turn, connect Power BI live to our AAS tabular model. To facilitate parallel processing, our fact table is partitioned by year, just like the source. We immediately realize the benefits of the increased connection limit in Azure SQL DW Gen 2 when the queries from AAS are processed simultaneously without queueing.
With this level of detail afforded to us, we can now zero-in on station-specific data and even analyze daily readings, if needed.

The last, but not least, feature of Azure SQL DW Gen 2 worth mentioning, is that as soon as our tabular model has finished processing, we can pause the data warehouse!
I hope this post has given some insights into how Azure SQL DW Gen 2 makes an already great data platform even better, and provided another example of how it fits into the Azure big data ecosystem.
Wondering what Azure can do for your organization? We can help! 3Cloud offers a wide spectrum of analytics solutions and support to help your group embrace data as a strategic asset. Contact us today to learn more.



