
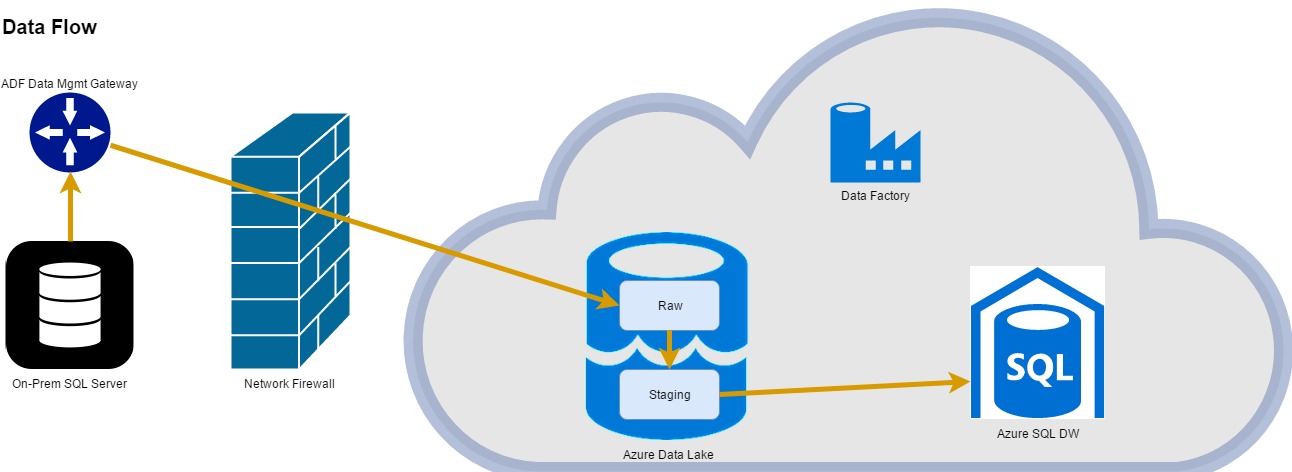
Many companies are implementing modern BI platforms including data lakes and PaaS (Platform as a Service) data movement solutions. Microsoft offers Azure Data Factory and Azure Data Lake in this space, which can be used to efficiently move your data to the cloud and then archive and stage it for further integration, reporting, and analytics.

There is good documentation on Microsoft Docs to help you get started with Azure Data Factory (ADF), but there is quite a bit to learn, especially if you are getting into ADF from an Integration Services (SSIS) background. Here are four tips for moving your data to Azure Data Lake Store with Azure Data Factory.
- Use service principal authentication in your linked service used to connect to Azure Data Lake Store. Azure Data Lake Store uses Azure Active Directory for authentication. As of April 2017, we can use service principal authentication in an Azure Data Factory linked service used to connect to Azure Data Lake Store. This alleviates previous issues where tokens expired at inopportune times and removes the need to manage another unattended service account in Azure Active Directory. Creating the service principal can be automated using PowerShell.

- The Azure Data Factory Copy Activity can currently only copy files to Azure Data Lake Store, not delete or move them (i.e., copy and delete). If you are using Azure Data Lake Store as a staging area for Azure SQL Data Warehouse and doing incremental loads using PolyBase, you may want to load only the changes that have occurred in the last hour or day into a staging area.
You are probably using dynamic folders and file names in your Azure Data Factory datasets to organize the data in the archive area of your data lake (perhaps by subject area, source system, dataset, date, and time). If you need to keep just the last set of changes to the source data in your staging area, you can remove the date and time portions of the filename to have one file per dataset. If you use the same filename and location, you can replace a file by overwriting it (removing the need to delete). Although your first inclinication might be to copy the data to staging and then archive, if you write your data to your archive area first and then copy it to staging, you can make sure your pipelines can be successfully re-run for previous time slices without having to re-query your source system.

If you find that you do indeed need a way to move or delete files in Azure Data Lake Store using Azure Data Factory, you can write a custom activity to accomplish this.

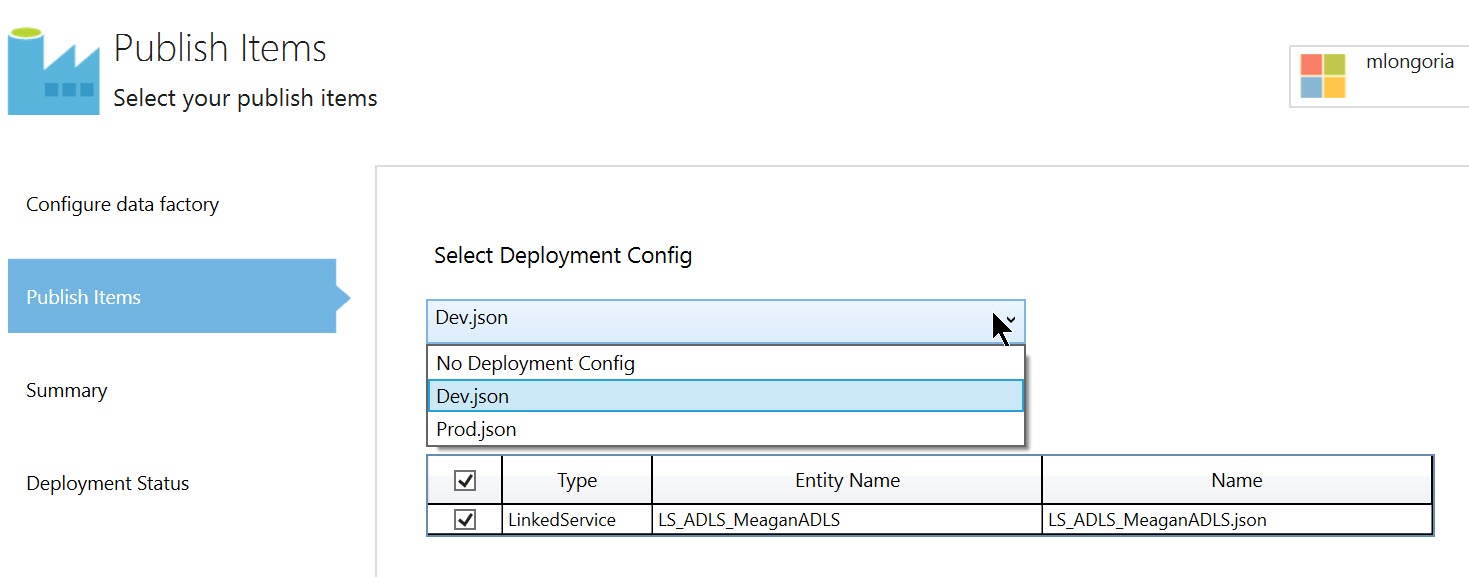
- Use configuration files to assist in deploying to multiple environments (dev/test/prod). Configuration files are used in Data Factory projects in Visual Studio. When Data Factory assets are published, Visual Studio uses the content in the configuration file to replace the specified JSON attribute values before deploying to Azure. A Data Factory config file is a JSON file that provides a name-value pair for each attribute that changes based upon the environment to which you are deploying. This could include connection strings, usernames, passwords, pipeline start and end dates, and more. When you publish from Visual Studio, you can choose the appropriate deployment configuration through the deployment wizard.

- While you can use the Azure .NET SDK to programmatically generate Data Factory assets, you can also automate the tedious creation of your pipelines with BimlScript. BimlScript is better known for automating SSIS development, but it can be used to automate ADF development as well. Exporting many tables/query results from a source system can mean hundreds of activities and datasets in your ADF project. You can save hours, even days, by using BimlScript to generate your datasets and pipelines. All you need is the free Biml Express add-in for Visual Studio and a bit of metadata.
By querying the metadata in your source system or creating a list in Excel, you can generate pipelines with copy activities that copy data from each source table to a file in your Azure Data Lake Store all in one fell swoop. BimlScript is XML with C# mixed in where automation is needed. You can manually write one dataset and one pipeline and then use them as a template. Identify the parts of your datasets and pipeline that change for each table you want to export to ADLS and replace those values with a Biml code nugget. This could include the names of pipelines, activities, and datasets as well as source tables and schemas, pipeline execution frequency, and the source data column used for time slices. Automating this development process with BimlScript produces the same project files that would have been created manually, with no evidence of automation and no vendor lock-in requiring you to use BimlScript when you create more pipelines or alter the existing pipelines.
Want to know more about Azure Data Factory? Feel free to contact us and we will be happy to answer your questions.



