
I once heard a conference presenter quip that “the PDF is where data goes to die.” There is some truth in the aphorism, as PDF format is often used to make text unalterable. However, this feature can be a failure when trying to pull information from important documents. In this article, I will demonstrate a set of tools that can extract, compile, and visualize data from large swaths of intractable files – proving that even data on a PDF can have a second life.

Where to Start
It’s all too common for an organization to have business-critical information on rigid file types or even paper. Digitization may be a clear first step, but what comes after that? Let’s consider one such scenario, where a company wants to identify insights from a set of text-embedded and scanned invoices. The below diagram outlines the process with three components: extraction, orchestration, and visualization. We will look at these in turn, along with the tools that make them possible.
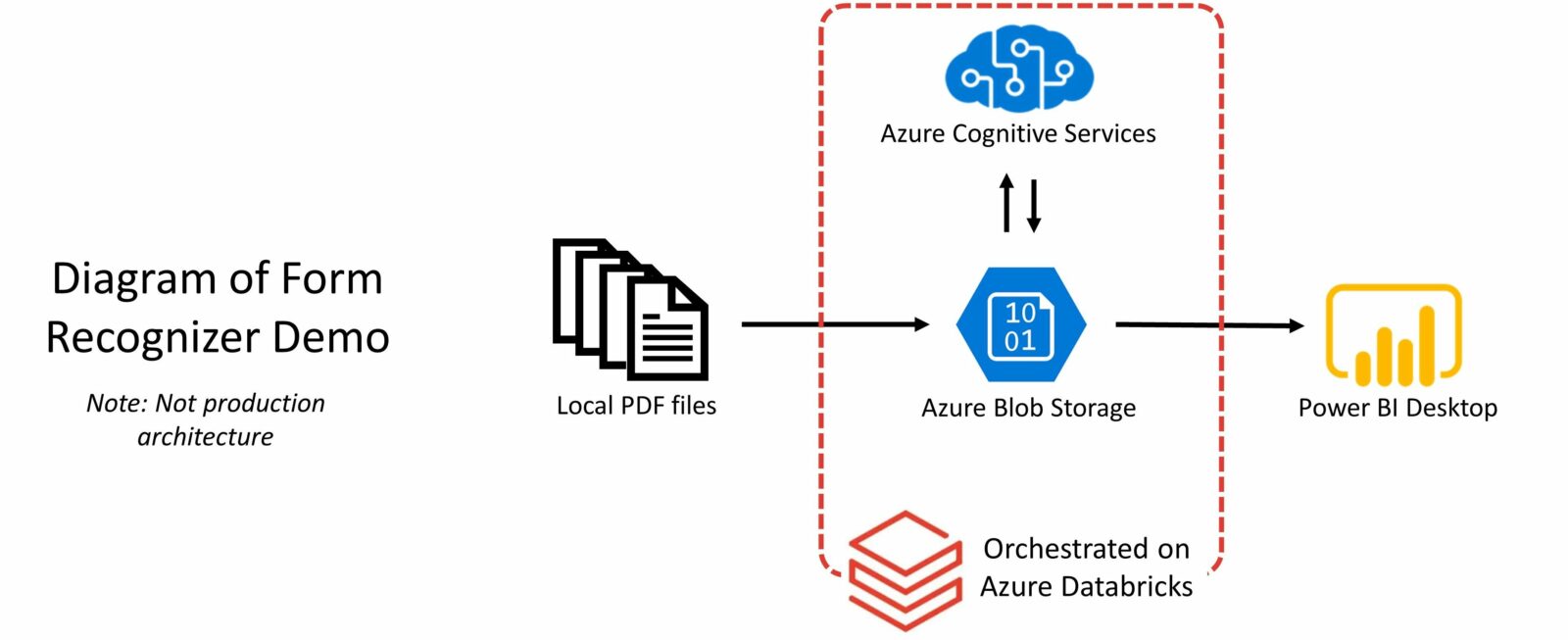
Extraction
The secret sauce behind data extraction at scale features Azure Cognitive Services. This key ingredient is a series of pretrained machine learning models that cover a variety of areas, from text analytics to speech translation. There is also a set of computer vision models and importantly, for our purposes, Form Recognizer.
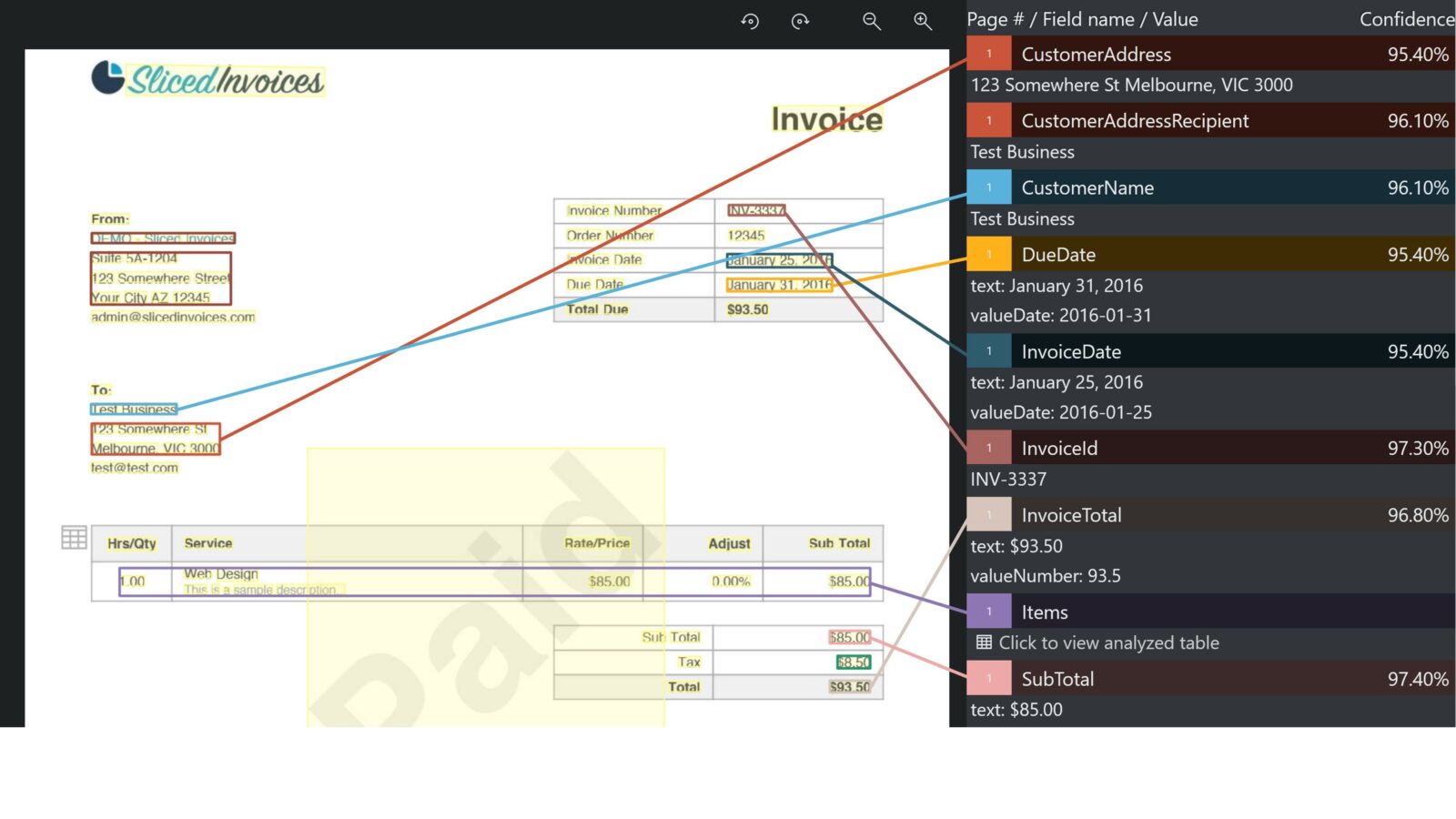
Form Recognizer extracts text from a variety of file types. It has some specific models that were trained on common use cases, such as invoices, receipts, business cards and IDs. A user can select any of these models or use a generic one to extract text from another document type, such as a letter. Form Recognizer even includes an Optical Character Recognition (OCR) to identify handwritten text.
The below example shows the Form Recognizer UI extracting data from a single, handwritten invoice. Documents can also be sent in batches to Cognitive Services via an API call and returned as scored results.
Orchestration
To scale up this process, we need a tool that that can batch files, send them to Cognitive Services with the right credentials, collect results, and then save those results for later analysis. Enter Azure Databricks, a data analytics platform that leverages Microsoft’s cloud resources and the Apache Spark language.
I create a Databricks notebook that performs each stepwise task within a chunk of code. The PDF files used here are located within an Azure blob storage container, meaning everything thus far is being done on the cloud, allowing for greater scalability and security. After sending the invoices to Form Recognizer, the files are run through the machine learning model, and scored results are sent back in JSON format. I then parse through to save key details such as customer information, vendor information, dates, and dollar amounts to a CSV file.
Visualization
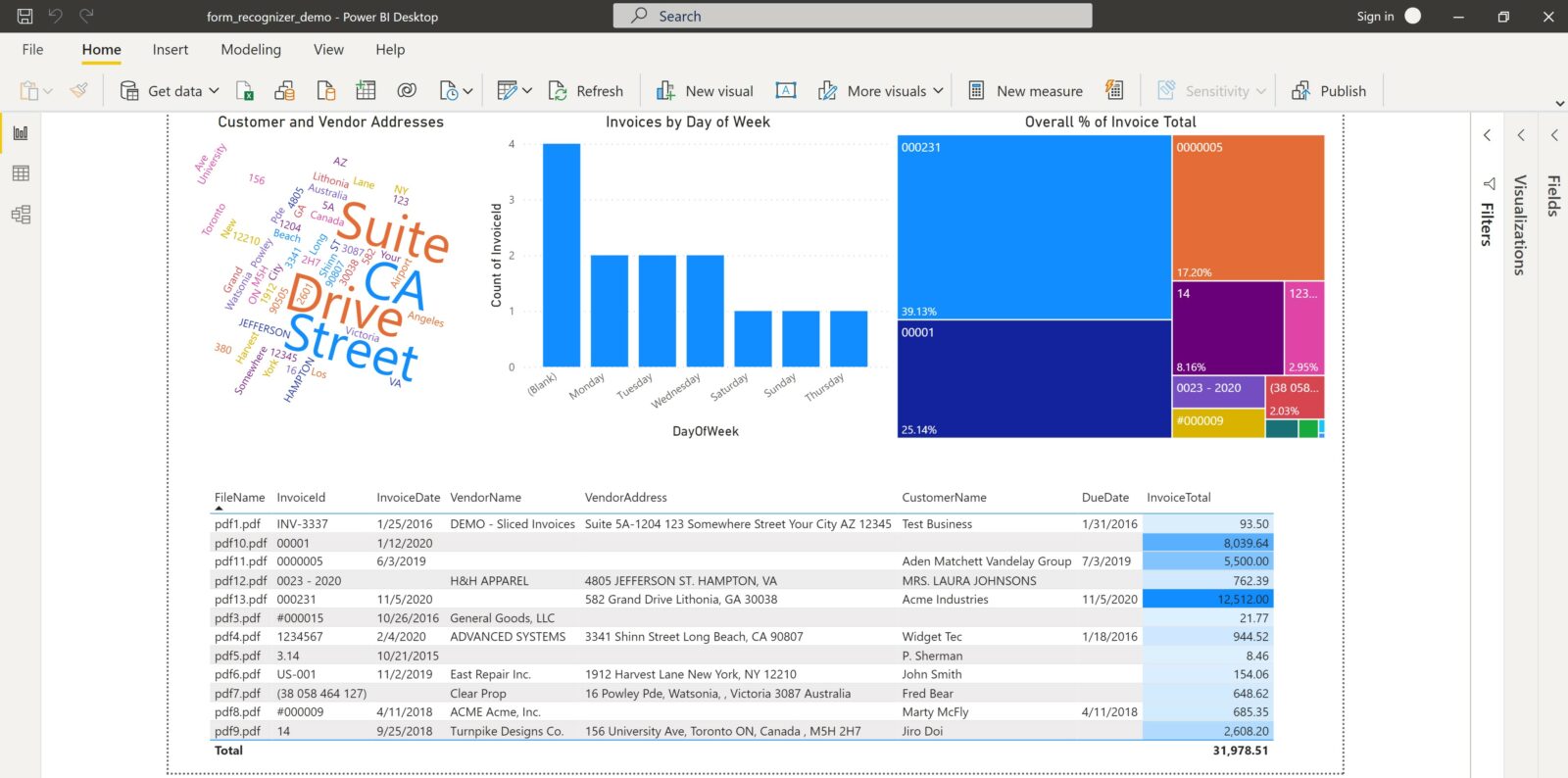
Databricks notebooks can effortlessly analyze and visualize data, as my colleague has aptly shown before. However, I’ll consider in this scenario that the example company already widely uses Power BI and requested that the results be presented there. I can do this by directly accessing the spreadsheet of scored results located on Azure storage.
From there, I build the below mock-up of the aggregated invoice data. Although the report is rather simple, it shows some overall trends in the data, as well as the current state of invoices within the company.
In Conclusion
We saw how the above collection of tools can easily unlock data with PDFs. Once new invoices are added to storage, a user only has to rerun the Databricks notebook and refresh the Power BI to update the report. Although a production-level solution would require a more advanced architecture, it will still follow the same basic structure shown here.
You can check out all the resources mentioned in this demo here and watch a full demonstration of this process in the below recording.
We Can Help!
Our data experts can help you learn more about consolidating your data from PDFs and show how the process greatly improves your overall business outcomes. Contact 3Cloud today.



